从转录稿到带类型的待办项:用 TypeScript 跑三个并行智能体
你的会议纪要工具,正在一个提示里悄悄干三份活
用 LLM 总结一场会议,常规做法是一个提示:「这是转录稿——给我一份摘要、把待办项挑出来、再告诉我每个人的情绪。」一次调用,一个模型,回来一团文本。
这在 demo 上能跑,到了真实转录稿上就开始散架。这是三份不同的活,三种不同的形状。摘要想以散文流动。待办项想是一份严格的清单,每一行都挂着负责人。情绪想给每个发言人一个判定。把它们塞进一个提示,它们就会打架:模型把摘要的内容灌进待办项,或者忘了给某个发言人打标签,或者「待办项」回来是一段你现在得手动去解析的文字。你还得为这一切串行付费,而当你想要的有一半本该是结构化数据时,回来的却是无结构的文本。
有个更干净的写法。跑三个专职选手,每个只干一份活,每个用自己的温度,其中两个返回带类型的对象而非散文——并且让它们同时跑,因为谁都不需要另一个的输出。然后第四个智能体把三份结果合并成一份报告。
这篇就照着 open-multi-agent 里的 meeting-summarizer cookbook 示例把这套东西搭出来。整个东西约 280 行 TypeScript,而并行才是重点。
你能从中得到什么
最终产物是一份形状固定的 Markdown 报告——一段散文摘要、一张待办项表格、按人列出的情绪,以及综合出的后续步骤。下面是一次真实运行的待办项部分,对象是一份 21 行的工程站会记录——每一行回来都是带类型的数据,不是脚本得去解析的散文:
| Task | Owner | Due |
|---|---|---|
| Deploy shadow-write harness for billing-v2 migration | Raj | 2026-04-24 |
| Add covering index to reconciliation query before cutover | Raj | 2026-04-28 |
| Flip feature flag for checkout redesign to 5% traffic | Priya | 2026-04-23 |
| Draft proposal for mandatory second reviewer on multi-region changes | Dan | 2026-04-27 |
| Create handoff doc for primary on-call rotation | Dan | — |
| Follow up with Len about authz refactor timeline | Maya | — |
完整报告还带着三段式摘要、一份按发言人的情绪解读,以及一份综合出的「后续步骤」清单。这一切都由四个智能体产出——其中三个并发跑过。下面讲它是怎么接起来的。
三个专职选手,一份转录稿
每个专职选手都是一个普通的 Agent,有自己的系统提示和温度。先从摘要器开始——输出散文,没有 schema,温度略高一点,好让它读起来自然:
const summaryConfig: AgentConfig = { name: 'summary', model: 'claude-sonnet-4-6', systemPrompt: `You are a meeting note-taker. Given a transcript, produce athree-paragraph summary:
1. What was discussed (the agenda).2. Decisions made.3. Notable context or risk the team should remember.
Plain prose. No bullet points. 200-300 words total.`, maxTurns: 1, temperature: 0.3,}另外两个专职选手,正是这套东西从「调三次 LLM」升级为「可靠」的地方:它们返回带类型的对象,不是文本。 你声明一个 Zod schema,把它作为 outputSchema 交给智能体,再从 result.structured 上读出解析好的结果。
待办项是一份清单,每一项都必须带负责人。截止日期是可选的,因为真实会议只是偶尔会点到一个:
const ActionItemList = z.object({ items: z.array( z.object({ task: z.string().describe('The action to be taken'), owner: z.string().describe('Name of the person responsible'), due_date: z.string().optional().describe('ISO date or human-readable due date if mentioned'), }), ),})
const actionItemsConfig: AgentConfig = { name: 'action-items', model: 'claude-sonnet-4-6', systemPrompt: `You extract action items from meeting transcripts. An actionitem is a concrete task with a clear owner. Skip vague intentions ("we shouldthink about X"). Include due dates only when the speaker named one explicitly.
Return JSON matching the schema.`, maxTurns: 1, temperature: 0.1, outputSchema: ActionItemList,}注意这个温度:0.1。抽取不是发挥创意的地方——你要的是同一份转录稿每次都给出同样的待办项。又因为设了 outputSchema,result.structured 回来就是一个带类型的 { items: [...] },你可以直接推进 Jira 或 Linear。没有正则,没有「解析那张模型但愿能产出的 markdown 表格」。
情绪是同一个思路,外加一道更紧的约束——tone 是个枚举,所以模型只能返回四个值之一,而且每个判定都得引用证据:
const SentimentReport = z.object({ participants: z.array( z.object({ participant: z.string().describe('Name as it appears in the transcript'), tone: z.enum(['positive', 'neutral', 'negative', 'mixed']), evidence: z.string().describe('Direct quote or brief paraphrase supporting the tone'), }), ),})evidence 字段是一道廉价的幻觉防线:逼模型给每个情绪附上一句引文,能让它别去编一个没人表达过的情绪。(如果你要照搬,有一个命名上的坑:外层的键是复数——items 和 participants——数组都挂在它们下面。)
扇出:让三个一起跑
三个专职选手谁都不依赖另一个——它们都读同一份转录稿,写各自独立的输出。这是扇出(fan-out)的教科书条件。open-multi-agent 的 AgentPool 能在一个上限内并发跑智能体;给它三个槽位,把智能体加进去,再用 Promise.all 把它们全部启动:
function buildAgent(config: AgentConfig): Agent { const registry = new ToolRegistry() registerBuiltInTools(registry) const executor = new ToolExecutor(registry) return new Agent(config, registry, executor)}
const pool = new AgentPool(3) // three specialists can run concurrentlypool.add(buildAgent(summaryConfig))pool.add(buildAgent(actionItemsConfig))pool.add(buildAgent(sentimentConfig))
const specialists = ['summary', 'action-items', 'sentiment'] as const
const parallelStart = performance.now()const timed = await Promise.all( specialists.map(async (name) => { const t = performance.now() const result = await pool.run(name, TRANSCRIPT) return { name, result, durationMs: performance.now() - t } }),)const parallelElapsed = performance.now() - parallelStart有一个值得知道的细节:AgentPool 持有一个按智能体的锁,所以同一个智能体不能同时跑两次——但三个不同名的智能体是真正并行的。池大小取 3,刚好够装下它们。
接下来是多数扇出教程会跳过的部分:证明它真的并行跑了。 量两个数——整个 Promise.all 外围的墙钟时间,以及每个智能体各自耗时之和。如果工作真的重叠了,墙钟时间会远小于这个和:
const serialSum = timed.reduce((acc, r) => acc + r.durationMs, 0)console.log(`Parallel wall time: ${Math.round(parallelElapsed)}ms`)console.log(`Serial sum (per-agent): ${Math.round(serialSum)}ms`)console.log(`Speedup: ${(serialSum / parallelElapsed).toFixed(2)}x`)
if (parallelElapsed >= serialSum * 0.7) { console.error('ASSERTION FAILED: parallel wall time is not < 70% of serial sum.') process.exit(1)}最后那段是有意为之的,值得你在自己的版本里留着。它是一道并行自检:如果那三次调用没有充分重叠——比方说你的服务商对你限了流、悄悄把请求串行化了——墙钟时间就会向那个串行和爬过去,脚本随之以非零状态退出。所以你跑这个看到 ASSERTION FAILED,那通常不是代码的 bug;是这道检查在尽职,告诉你扇出退化成了排队。
在一次对着 DeepSeek 的真实运行里,三个专职选手重叠出了 2.21× 的加速——11.7 秒墙钟时间对 25.9 秒的各智能体耗时之和。这个确切数字会随模型延迟和网络浮动,而这正是「按每次运行实测、而非引用一个手册数字」的意义所在。
第四个智能体:聚合器
扇出给你三份并行的结果。你还得把它们合并成一份报告——这是第四个智能体,跑在其它三个之后,因为它依赖全部三份。别藏着掖着:这个模式是三并行加一,不是三。
聚合器把散文摘要当文本、两份结构化结果当 JSON 收进来,并被要求产出一份固定四级标题的报告:
const aggregatorPrompt = `Merge the three analyses below into a single Markdown report.
--- SUMMARY (prose) ---${byName.get('summary')!.output}
--- ACTION ITEMS (JSON) ---${JSON.stringify(actionData, null, 2)}
--- SENTIMENT (JSON) ---${JSON.stringify(sentimentData, null, 2)}
Produce the Markdown report per the system instructions.`
const reportResult = await pool.run('aggregator', aggregatorPrompt)它的系统提示钉死了输出结构(## Summary / ## Action Items / ## Sentiment / ## Next Steps,待办项做成一张表格),并加了一条重要规则:不要编造没有其它数据支撑的待办项。 聚合器的活是格式化并综合出后续步骤,不是去发现新事实——那行字让它别跑偏。
一次真实运行
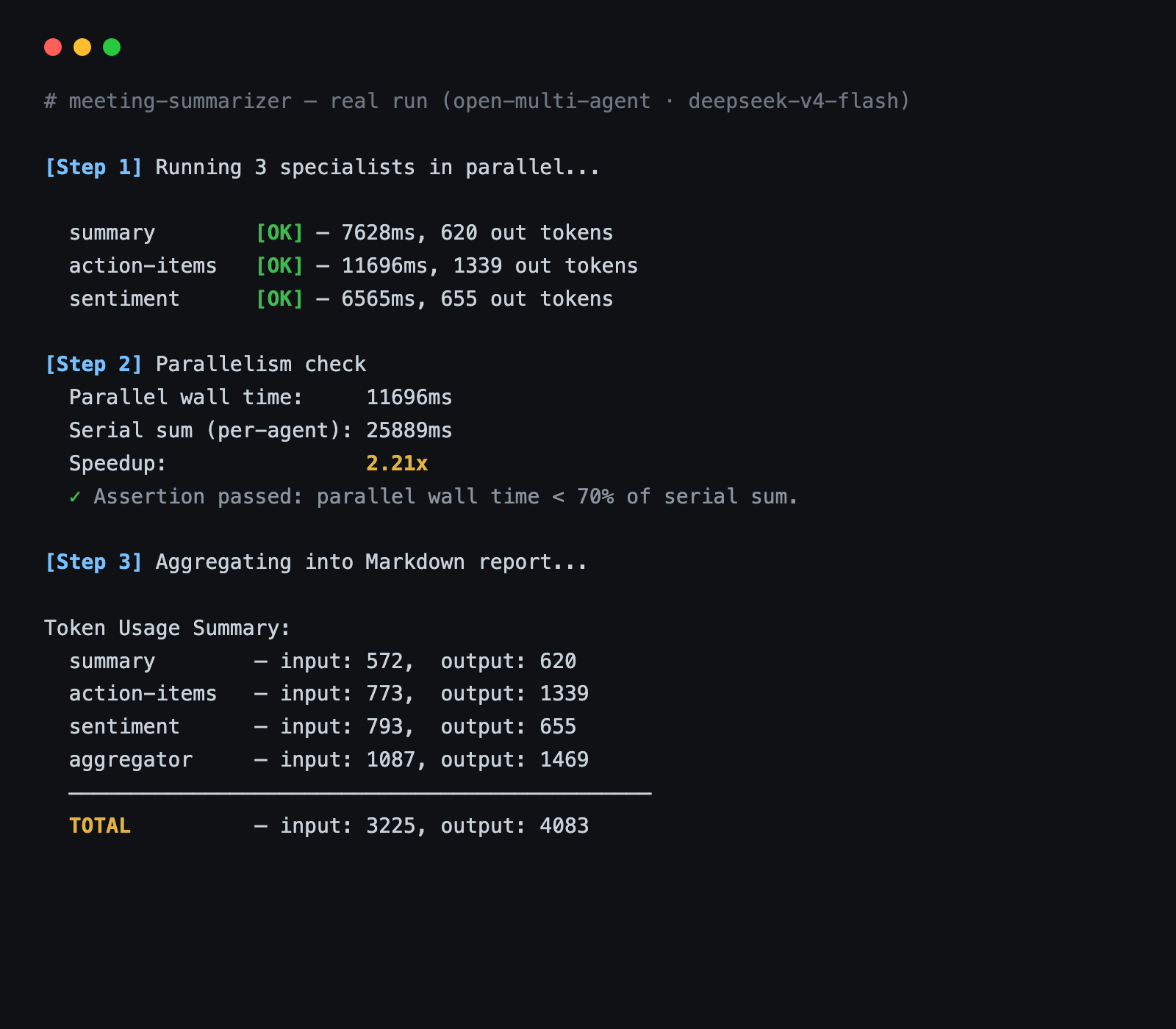
示例随附的是 claude-sonnet-4-6;这些数字来自一次换成 DeepSeek(deepseek-v4-flash)的运行——智能体的配置完全相同,只换了 model id。三个专职选手扇出,action-items 和 sentiment 的输出对着各自的 Zod schema 校验通过,聚合器产出了上面那份报告。整次运行的 token 用量——三个专职选手加聚合器——是 3,225 输入和 4,083 输出 token。(那是 token 计数,不是一个美元数字;你付多少取决于你的服务商和模型。)
有一点要把预期摆正:扇出给你买到的是墙钟时间,不是 token。 你照样做四次模型调用——只是不再一个接一个地等它们。而且你还多加了一次调用(聚合器),这是单个提示本不会有的。在一份很小的转录稿上,协调开销能把这点收益吃掉;这个模式真正回本,是随着每个专职选手自己的活变大。
这个模式什么时候合适——什么时候不合适
该上扇出的时候,是一份输入需要好几份相互独立的分析。会议 → {摘要, 待办项, 情绪} 是典型案例,但 PR → {安全审查, 风格审查, 测试覆盖检查} 也是,支持工单 → {分类, 紧急度, 建议回复} 也是。相互独立的活,同一个来源,你想拿到下游去用的带类型输出。
别这么干,当步骤彼此依赖时——先调研再写作是一条流水线,不是扇出,硬把它并行只会打断数据流。也别为扇出而扇出地把一份活拆开:一个智能体比一个池子加一个聚合器更简单。
同一个框架里还有一个更高阶的选项。这篇里你是手工接的并行——由你来决定什么并发跑。如果你更想描述一个目标、让一个协调器把它拆成一张任务 DAG 并替你把那个并行掉,那正是 runTeam() 做的事;我在《目标进,DAG 出》里写过。像这篇这样手工接的扇出,在形状固定、你想要它显式时是对的选择;协调器则在形状随目标而变时是对的选择。
跑起来
npm install @open-multi-agent/core完整示例在仓库里——从仓库根目录跑(它需要 ANTHROPIC_API_KEY):
npx tsx packages/core/examples/cookbook/meeting-summarizer.ts可读的源码:meeting-summarizer 示例及其转录稿固件。想看同样的扇出/聚合形状剥到只剩骨架的版本,见 fan-out-aggregate 模式。
一个诚实的提醒:这里的转录稿是一份合成的站会记录,而项目的生产验证还很早期。如果你把它指向真实会议,我很想听听这套带类型的抽取在哪里扛住了、在哪里没扛住。