用 TypeScript 跑一支 100% 本地的多智能体团队(Ollama + Gemma,$0 API 成本)
API 账单就是一张数据外泄回执
你的智能体每次调用托管模型,同时是两件事:账单上的一行,以及你输入的一份副本落到别人的服务器上。对很多 AI 功能来说,这笔交易没问题。但对某些——内部日志、客户记录、任何落在合规约束下的东西,或者只是一个你不想被计量收费的业余项目——就不行。
常规答案是「把模型跑在本地」,而人们默认这意思是工作智能体在本地跑、云端某个更聪明的东西仍然负责思考。这篇更进一步:协调器——那个读取目标、把它拆解成任务图、再派发工作者的智能体——本身就是一个跑在你笔记本上的约 5B 模型。回路里完全没有云。零 API 成本,数据一步都不离开机器。
我会给你看那一行让本地模型变成一等公民的代码,在 Gemma 4 上搭一支完全本地的团队,证明本地协调器真的拆解了目标(而不是框架悄悄替它兜底),然后诚实交代两件咬人的事:内存,和一个思考模型的怪癖。最后是一个混合变体——云端编码者、本地评审员——附一个我复现出来的失败和确切的修法。
下面这一切都跑在一台 Apple M1 / 16 GB 上,gemma4:e2b 走 Ollama。这些数字来自一次实测运行,不是宣传册。
唯一动作:把 baseURL 指向一个本地端点
open-multi-agent 通过 OpenAI 兼容协议和模型对话。每个正经的本地运行时也都讲这套协议。所以「用一个本地模型」不是一次集成——它是智能体配置上的三个字段:复用 openai 这个 provider、设好 model、把 baseURL 指向本地服务器。
import { OpenMultiAgent } from '@open-multi-agent/core'import type { AgentConfig } from '@open-multi-agent/core'
const researcher: AgentConfig = { name: 'researcher', model: 'gemma4:e2b', provider: 'openai', // OpenAI-compatible protocol, not the OpenAI cloud baseURL: 'http://localhost:11434/v1', // Ollama's OpenAI-compatible endpoint apiKey: 'ollama', // placeholder; Ollama ignores it, the OpenAI SDK just needs a non-empty string systemPrompt: `You are a system researcher. Use bash to run non-destructive,read-only commands (uname -a, sw_vers, df -h, uptime, etc.) and report results.`, tools: ['bash', 'file_write'], maxTurns: 8,}apiKey 是故意放的占位符:没有 key,但 SDK 需要一个非空字符串。baseURL 才是全部的诀窍,而且它对下面任何一个都成立——挑你的运行时,其余代码原封不动:
| 本地运行时 | OpenAI 兼容的 baseURL |
|---|---|
| Ollama | http://localhost:11434/v1 |
| vLLM | http://localhost:8000/v1 |
| LM Studio | http://localhost:1234/v1 |
| llama.cpp server | http://localhost:8080/v1 |
跑之前有一个环境上的坑:如果你设了 HTTP_PROXY,用 no_proxy=localhost 把 localhost 豁免掉,否则 SDK 会试图把你的本地模型调用经代理路由,然后卡住。
一支连协调器都在本地的团队
这个示例带了两种方式来跑同一支双角色团队(一个用 bash 收集系统信息的 researcher,一个把它们写成文的 summarizer)。两种都 100% 跑在 gemma4:e2b 上。
第一部分——DAG 归你(runTasks)。 你显式声明任务和它们的依赖;框架来调度:
const orchestrator = new OpenMultiAgent({ defaultModel: 'gemma4:e2b', maxConcurrency: 1, // a local model serves one request at a time})
const team = orchestrator.createTeam('explicit', { name: 'explicit', agents: [researcher, summarizer], sharedMemory: true,})
const result = await orchestrator.runTasks(team, [ { title: 'Gather system information', assignee: 'researcher', description: '...' }, { title: 'Summarize the report', assignee: 'summarizer', description: '...', dependsOn: ['Gather system information'] },])第二部分——DAG 归本地模型(runTeam)。 这才是真正的主张。你交给团队一句话的目标,让本地的 Gemma 充当协调器:由它决定拆解、分派对象和依赖关系。
// The coordinator is auto-created by runTeam(). These `default*` fields are what// keep it local too — they point the auto-created coordinator at Ollama, not the cloud.const orchestrator = new OpenMultiAgent({ defaultModel: 'gemma4:e2b', defaultProvider: 'openai', defaultBaseURL: 'http://localhost:11434/v1', defaultApiKey: 'ollama', maxConcurrency: 1,})
const team = orchestrator.createTeam('auto', { name: 'auto', agents: [researcher, summarizer], sharedMemory: true,})
// One natural-language goal; the local Gemma coordinator decomposes it and dispatches.const result = await orchestrator.runTeam( team, "Check this machine's Node.js version, npm version, and OS info, then write a short Markdown report.",)要让这个成立,一个 5.1B 的量化模型必须做到本地模型出了名做不好的两件事:产出一份语法上有效的 JSON 任务拆解,以及发起真实的工具调用。它两件都做到了。
证明是模型干的,不是回退
这里有个微妙之处,把一个真实结果和一个只是看起来像的 demo 区分开来。runTeam 有一张安全网:如果协调器的拆解解析失败,它会悄悄回退到一个每个智能体一个任务的琐碎计划。光一个绿勾什么都说明不了——你得证明这份计划来自模型。
这是 gemma4:e2b 真正产出的拆解,从模型原样捕获、并通过框架的 planOnly 路径复现(有效的 json 围栏,严格的 JSON.parse 成功):
[ { "title": "Gather System Information", "description": "Execute necessary bash commands (e.g., uname -a, sw_vers, node -v, npm -v) to collect the Node.js version, npm version, and OS information from the machine.", "assignee": "researcher", "dependsOn": [] }, { "title": "Generate Markdown Report", "description": "Read the collected system information and compile it into a concise Markdown summary report.", "assignee": "summarizer", "dependsOn": ["Gather System Information"] }]为什么这确实是模型、而不是回退:
- 这些标题是模型自己起的。 回退给任务起的名字形如
researcher: <goal…>;而被执行的任务是Gather System Information/Generate Markdown Report。 - 有一条真实的依赖。 summarizer 任务
dependsOnresearcher 任务——而每个智能体一个任务的回退从不创建依赖。一条依赖边只可能来自一次真实的拆解。 - 角色正确。 researcher 收集,summarizer 写作。模型明白了哪个智能体干哪份活。
- 四个一致的数据点。 两次完整的端到端运行(我插了桩的副本和未改动的随附文件),外加一次
runAgent原始输出探针和一次runTeam({ planOnly })探针——全都产出同一份有效的 2 任务拆解,全都报告fallback = false。
(给任何会去读原始证据 JSON 的人一条诚实的脚注:我第一遍插桩误报了一个 fallbackEngaged: true 标志,因为测量脚手架读到了一个塌缩的、空的 coordinator 键。上面那四个探针才是纠正它的东西——这个标志是我的测量 bug,不是框架的行为。我把这个标志连同一条注记留在了证据文件里、没有把它擦掉,因为对齐真相的过程实际上就长这样。)
一次真实运行——那本台账
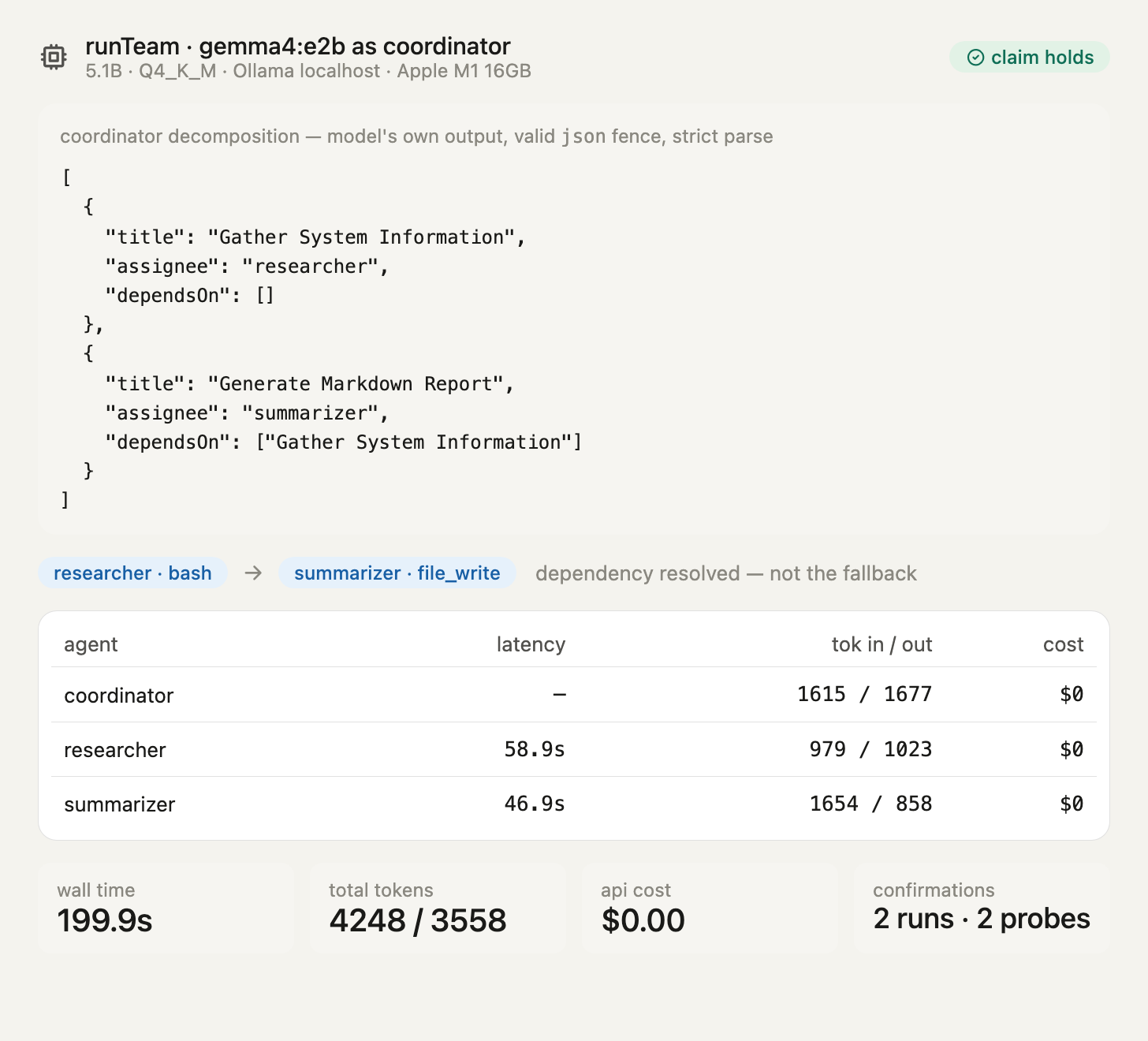
第二部分,带本地协调器的 runTeam,一次实测运行:
| 任务 | 智能体 | 模型 | 延迟 | 输入 tok | 输出 tok | 工具 | 成本 |
|---|---|---|---|---|---|---|---|
| (拆解 + 综合) | coordinator | gemma4:e2b | — | 1615 | 1677 | (无) | $0 |
| Gather System Information | researcher | gemma4:e2b | 58.9 s | 979 | 1023 | bash | $0 |
| Generate Markdown Report | summarizer | gemma4:e2b | 46.9 s | 1654 | 858 | file_write | $0 |
| 总计 | 199.9 s 墙钟 | 4248 | 3558 | $0 |
最终的 report.md 带着真实、正确的值——Node v22.22.3、npm 10.9.8、macOS 26.5(构建号 25F71)、Darwin 25.5.0 … arm64——所以工作者不只是跑了,它们产出了准确的输出。我把未改动的随附文件又跑了一遍作为第二次确认:结果一样,runTasks 182.4 秒、runTeam 155.5 秒,同样有效的拆解。
关于成本,诚实的标题是 $0;关于速度,是以分钟计,不是秒——往下读。
没人放进 demo 里的摩擦
这是你从供应商页面上得不到的部分,而如果你打算自己跑这套,它是最有用的部分。
1. 它是个「思考」模型——别把 maxTokens 压得太小。 gemma4:e2b 在给出答案之前,会在一个单独的通道里吐推理 token。我直接复现了这个陷阱:一次 max_tokens: 10 的调用返回了空内容——思考把整个预算吃光了。随附示例没设 maxTokens,所以走 Ollama 的默认值,能用。但如果你为省内存把 token 预算收紧,一个空的协调器响应,正是上一节那个悄悄回退的触发条件。在思考模型上,把 maxTokens 留宽裕。
2. 按约 16 GB 内存来规划,并预期会用到交换。 那个 7.16 GB 的 Q4 模型把我 16 GB 的机器逼进了交换(运行期间用掉约 6.8–7.3 GB)。它正确跑完了,但更大的 gemma4:e4b(9.6 GB)在这里会更糟。把预期摆正:e2b 想要 16 GB 却仍然会交换;再往大走,你就需要更多。
3. 慢,但能用。 每次调用的延迟在 5–25 秒;一次完整 demo(第一部分 + 第二部分)大约 6 分钟。对一个「$0、私密、跑一整夜」的故事来说这没问题;但它不是交互级的利落。
4. 没有量化病态——而且这个模型你不需要那些采样旋钮。 每一次运行里:零重复循环、零幻觉出来的工具 schema、零无效 JSON。仓库里的 local-quantized.ts 示例(topK / minP / repetition_penalty 调参)针对的是其它会出毛病的 MoE 量化模型——gemma4:e2b 用不上它。这倒是个漂亮的过渡,因为调参确实会在混合的情形里重新变得要紧。
转向混合:云端编码者,本地评审员(以及它在哪崩了)
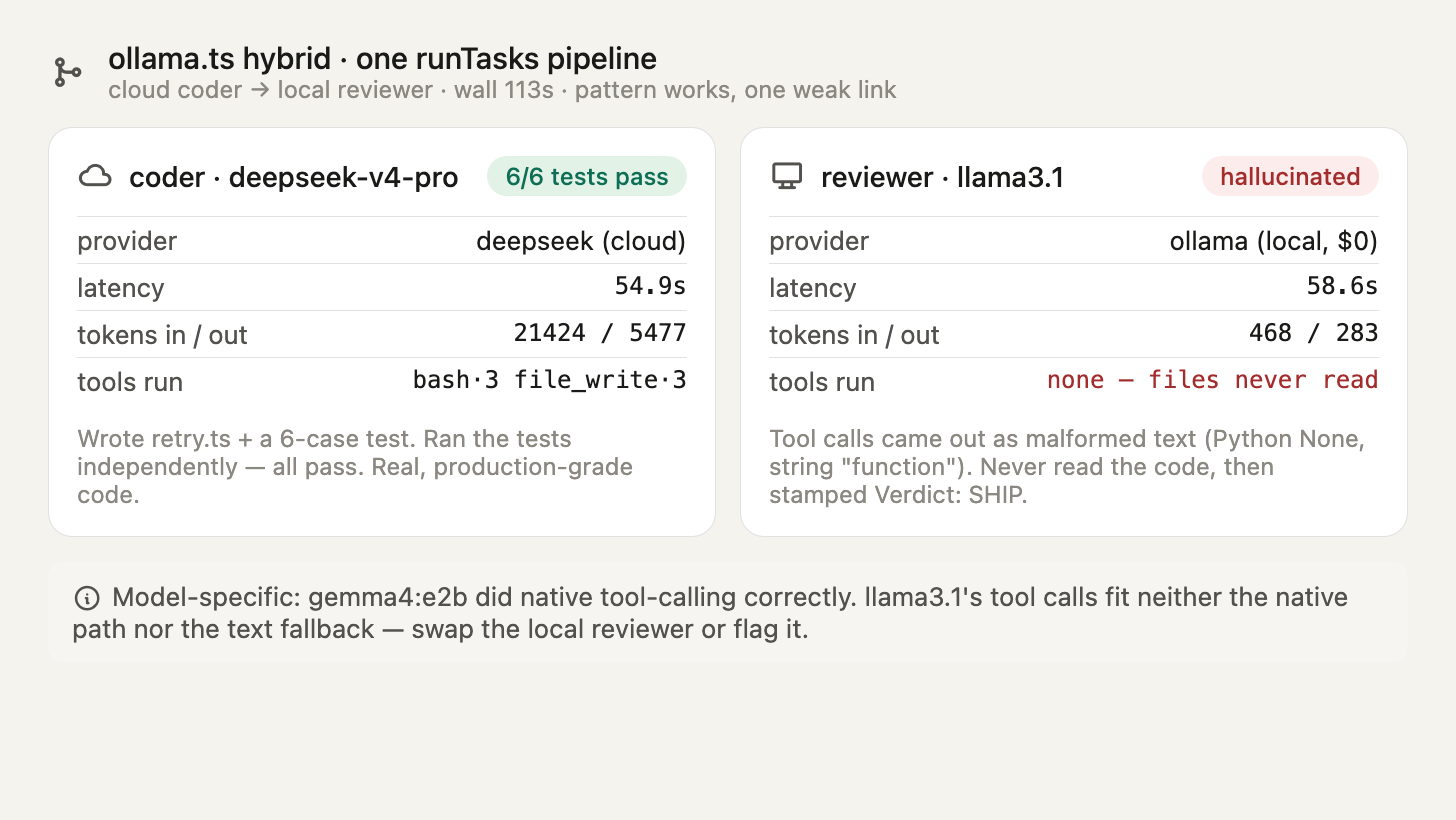
同一个 baseURL 诀窍,让你在一条流水线里把云端和本地混起来:把困难的、非敏感的活发给一个强的云端模型,其余留在本地。随附的 ollama.ts 做的正是这件事——一个编码者加一个评审员。我跑了一份忠实的副本,配一个云端编码者(DeepSeek)和随附的本地评审员(走 Ollama 的 llama3.1)。
| 智能体 | 供应商 | 模型 | 执行的工具 | 判定 |
|---|---|---|---|---|
| coder | deepseek(云) | deepseek-v4-pro | bash×3, file_write×3 | 优秀 |
| reviewer | ollama(本地) | llama3.1 | 无 | 幻觉 |
云端编码者是真的通过了。 DeepSeek 写了一个干净的 retry.ts(指数退避、shouldRetry、withRetry)和一个 6 用例的测试文件。我独立跑了测试:6 通过,0 失败。
本地的 llama3.1 评审员在实质上失败了——两次。 它从没读过文件(tools: [],约 468 个输入 token,而两个文件本该花约 2,400),然后幻觉出了一份评审:它把 TypeScript 代码称作「try-except 块」(那是 Python),把一个有 3 个导出的模块说成「单个函数」,还给 Verdict: SHIP 盖章放行。更糟的是,这次运行报告了 success: true。一份对它从没打开过的代码的自信评审。
确切的根因: llama3.1 没有发出原生的 tool_calls——它把调用当文本叙述了出来,而这段文本对那张安全网提取器来说是畸形的(一次运行里是无效 JSON,复现里是一个错误的 function-作为字符串的形状)。原生路径和回退都没触发,于是没有任何文件被读过。这是模型特定的:100% 本地示例里的 gemma4:e2b 发出了正确的原生工具调用,每个工具都执行了。
修好本地评审员:两部分的修法,不是换个模型
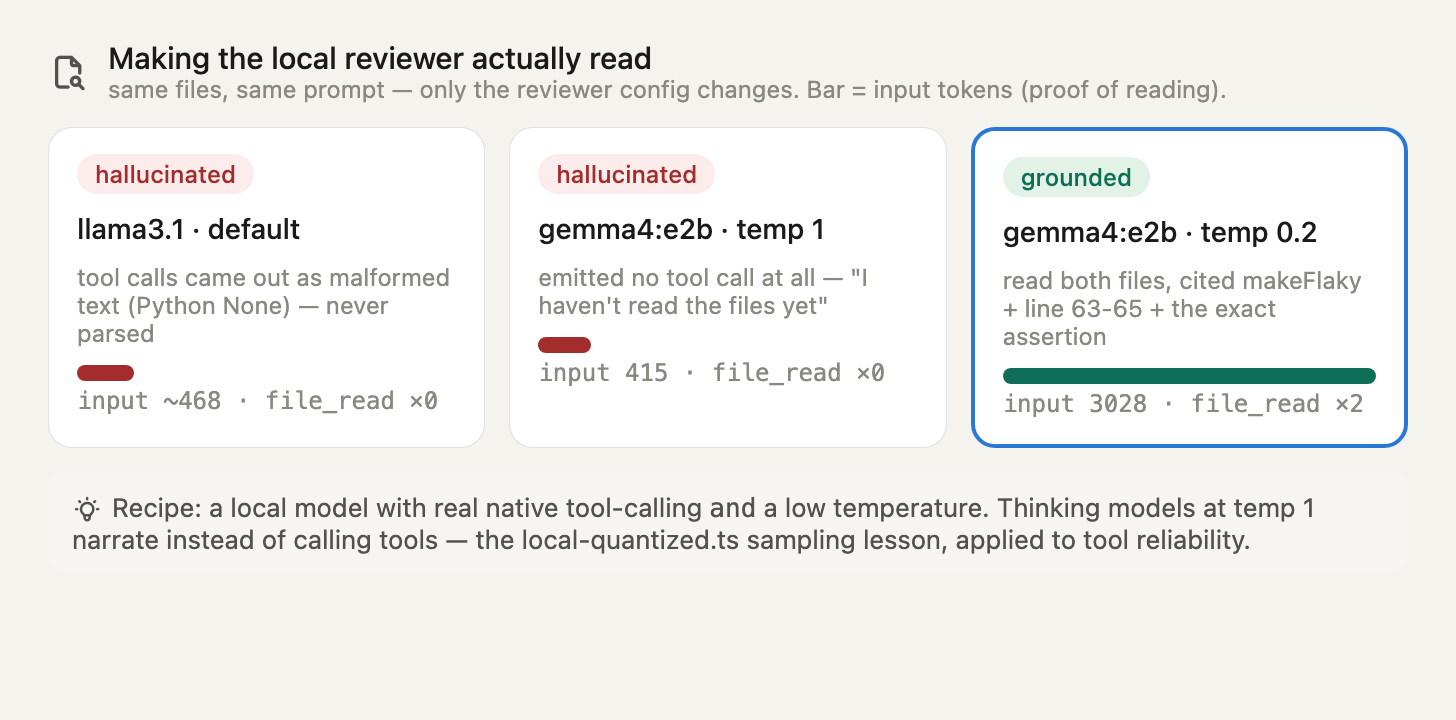
显而易见的修法是「把评审员换成一个有真正工具调用的模型」。必要,但不充分——温度同样要紧。同样的文件、同样的评审员提示,只改评审员配置:
| 评审员配置 | 执行的 file_read | 输入 tok | 结果 |
|---|---|---|---|
| llama3.1(默认) | 无 | 335–468 | 畸形的文本工具调用 → 幻觉评审 |
| gemma4:e2b @ temp 1(其默认) | 无 | 415 | 没发出工具调用 →「我还没读文件」 |
| gemma4:e2b @ temp 0.2, topP 0.9 | file_read ×2 | 3028 | 读了两个文件 → 有据可依的评审 |
只有最后一行真的读了代码——你能从输入 token 从 415 跳到 3028 看出来,也能从评审引用了真实的细节看出来(makeFlaky 辅助函数、位于 63–65 行的 testFailureExhaustion、那个确切的 'permanent failure' 断言字符串)。
为什么是温度?gemma4:e2b 是个思考模型,默认 temperature: 1。在温度 1 下,它随机地叙述了「我待会儿再读」、没发出工具调用,于是智能体回路一个回合就结束了。在温度 0.2 下,它确定性地遵循了「先读」。这和 local-quantized.ts 里「为本地模型驯服你的采样」是同一课——这里展示的是它主宰着工具调用的可靠性,不只是重复。一个能干活的本地评审员的配方:(1) 一个有真正原生工具调用的模型,以及 (2) 一个低温度。 两者齐备,本地评审员就真的会读、会审了,成本 $0。
什么时候该全本地,什么时候该混合
- 全本地,当数据驻留是硬约束时:什么都不离开机器、$0 成本,而且——如前所示——连协调器都能在本地。代价是内存和延迟(以分钟计,不是秒)。
- 混合,当某一步确实需要一个前沿模型(上面那个编码者)、但其余可以留在家里时。管路是可靠的——云端和本地在同一条
runTasks流水线里、经由baseURL。只要给你的本地智能体挑好扎实的原生工具调用、并驯服它们的温度,否则你会得到一个从没读过代码却很自信的评审员。
还有一个更高层的角度值得给个链接:在第二部分里我让本地模型成为协调器。如果你想了解在这个框架里一个目标是怎么变成任务 DAG 的机制,我在《目标进,DAG 出》里写过。这篇的惊喜在于,驱动那次拆解的模型可以是 5B 的、跑在你的笔记本上。
跑起来
npm install @open-multi-agent/core你需要 Ollama 跑着、并且模型已经拉下来:
ollama pull gemma4:e2b # ~7 GB; wants ~16 GB RAM to run comfortably# then run the example from the repo (remember: no_proxy=localhost if you use a proxy)三个示例文件,按辣度递增来读:gemma4-local.ts(100% 本地,runTasks 和 runTeam 都有)、local-quantized.ts(给会出毛病的 MoE 量化模型用的采样旋钮),以及 ollama.ts(混合——云端 + 本地在一条流水线里)。
一个诚实的提醒:本地工具调用的可靠性因模型差异很大——gemma4:e2b 很扎实,llama3.1 在这个任务里不行——而且这个项目的生产验证还很早期。如果你自己跑一支本地团队,我很想听听哪些本地模型发出了干净的原生工具调用、哪些没有。