A 100% Local Multi-Agent Team in TypeScript (Ollama + Gemma, $0 API Cost)
The API bill is a data-exfiltration receipt
Every call your agents make to a hosted model is two things at once: a line on an invoice, and a copy of your input landing on someone else’s server. For a lot of AI features that trade is fine. For some — internal logs, customer records, anything under a compliance regime, or just a side project you don’t want metered — it isn’t.
The usual answer is “run the model locally,” and people assume that means the worker agents run locally while something smarter in the cloud still does the thinking. This post goes further: the coordinator — the agent that reads a goal, decomposes it into a task graph, and dispatches the workers — is itself a ~5B model running on your laptop. No cloud in the loop at all. Zero API cost, and the data never leaves the machine.
I’ll show the one line that makes local models first-class, build a fully-local team on Gemma 4, prove the local coordinator actually decomposed the goal (rather than the framework quietly covering for it), and then be honest about the two things that bite: RAM and a thinking-model quirk. At the end, a hybrid variant — cloud coder, local reviewer — with a failure I reproduced and the exact fix.
Everything below was run on an Apple M1 / 16 GB, gemma4:e2b over Ollama. The numbers are from one measured run, not a brochure.
The one move: point baseURL at a local endpoint
open-multi-agent talks to models through the OpenAI-compatible protocol. Every serious local runtime speaks that protocol too. So “use a local model” is not an integration — it’s three fields on an agent config: reuse the openai provider, set model, and point baseURL at the local server.
import { OpenMultiAgent } from '@open-multi-agent/core'import type { AgentConfig } from '@open-multi-agent/core'
const researcher: AgentConfig = { name: 'researcher', model: 'gemma4:e2b', provider: 'openai', // OpenAI-compatible protocol, not the OpenAI cloud baseURL: 'http://localhost:11434/v1', // Ollama's OpenAI-compatible endpoint apiKey: 'ollama', // placeholder; Ollama ignores it, the OpenAI SDK just needs a non-empty string systemPrompt: `You are a system researcher. Use bash to run non-destructive,read-only commands (uname -a, sw_vers, df -h, uptime, etc.) and report results.`, tools: ['bash', 'file_write'], maxTurns: 8,}apiKey is a placeholder on purpose: there’s no key, but the SDK requires a non-empty string. The baseURL is the whole trick, and it works against any of these — pick your runtime, keep the rest of the code identical:
| Local runtime | OpenAI-compatible baseURL |
|---|---|
| Ollama | http://localhost:11434/v1 |
| vLLM | http://localhost:8000/v1 |
| LM Studio | http://localhost:1234/v1 |
| llama.cpp server | http://localhost:8080/v1 |
One environment gotcha before you run anything: if you have an HTTP_PROXY set, exempt localhost with no_proxy=localhost, or the SDK will try to route your local model calls through the proxy and hang.
A team where even the coordinator is local
The example ships two ways to run the same two-role team (a researcher that gathers system facts with bash, a summarizer that writes them up). Both run 100% on gemma4:e2b.
Part 1 — you own the DAG (runTasks). You declare the tasks and their dependencies explicitly; the framework schedules them:
const orchestrator = new OpenMultiAgent({ defaultModel: 'gemma4:e2b', maxConcurrency: 1, // a local model serves one request at a time})
const team = orchestrator.createTeam('explicit', { name: 'explicit', agents: [researcher, summarizer], sharedMemory: true,})
const result = await orchestrator.runTasks(team, [ { title: 'Gather system information', assignee: 'researcher', description: '...' }, { title: 'Summarize the report', assignee: 'summarizer', description: '...', dependsOn: ['Gather system information'] },])Part 2 — the local model owns the DAG (runTeam). This is the real claim. You hand the team a one-line goal and let the local Gemma act as coordinator: it decides the decomposition, the assignees, and the dependencies.
// The coordinator is auto-created by runTeam(). These `default*` fields are what// keep it local too — they point the auto-created coordinator at Ollama, not the cloud.const orchestrator = new OpenMultiAgent({ defaultModel: 'gemma4:e2b', defaultProvider: 'openai', defaultBaseURL: 'http://localhost:11434/v1', defaultApiKey: 'ollama', maxConcurrency: 1,})
const team = orchestrator.createTeam('auto', { name: 'auto', agents: [researcher, summarizer], sharedMemory: true,})
// One natural-language goal; the local Gemma coordinator decomposes it and dispatches.const result = await orchestrator.runTeam( team, "Check this machine's Node.js version, npm version, and OS info, then write a short Markdown report.",)For that to work, a 5.1B quantized model has to do the two things local models are notoriously bad at: emit a syntactically valid JSON task decomposition, and make real tool calls. It did both.
Proof it was the model, not the fallback
Here’s the subtlety that separates a real result from a demo that only looks like one. runTeam has a safety net: if the coordinator’s decomposition fails to parse, it silently falls back to a trivial one-task-per-agent plan. A green checkmark alone tells you nothing — you have to prove the plan came from the model.
This is the decomposition gemma4:e2b actually produced, captured raw from the model and reproduced through the framework’s planOnly path (valid json fence, strict JSON.parse succeeds):
[ { "title": "Gather System Information", "description": "Execute necessary bash commands (e.g., uname -a, sw_vers, node -v, npm -v) to collect the Node.js version, npm version, and OS information from the machine.", "assignee": "researcher", "dependsOn": [] }, { "title": "Generate Markdown Report", "description": "Read the collected system information and compile it into a concise Markdown summary report.", "assignee": "summarizer", "dependsOn": ["Gather System Information"] }]Why this is genuinely the model and not the fallback:
- The titles are the model’s own. The fallback names tasks like
researcher: <goal…>; the executed tasks wereGather System Information/Generate Markdown Report. - There’s a real dependency. The summarizer task
dependsOnthe researcher task — and the one-task-per-agent fallback never creates dependencies. A dependency edge can only come from a real decomposition. - Correct roles. Researcher gathers, summarizer writes. The model understood which agent does what.
- Four consistent data points. Two full end-to-end runs (my instrumented copy and the unmodified shipped file), plus a
runAgentraw-output probe and arunTeam({ planOnly })probe — all produced the same valid 2-task decomposition, all reportingfallback = false.
(One honest footnote for anyone who reads the raw evidence JSON: my first instrumentation pass false-positived a fallbackEngaged: true flag, because the harness read a collapsed, empty coordinator key. The four probes above are what corrected it — the flag is my measurement bug, not the framework’s behavior. I left the flag in the evidence file with a note rather than scrub it, because that’s what the ground-truthing actually looked like.)
One real run — the ledger
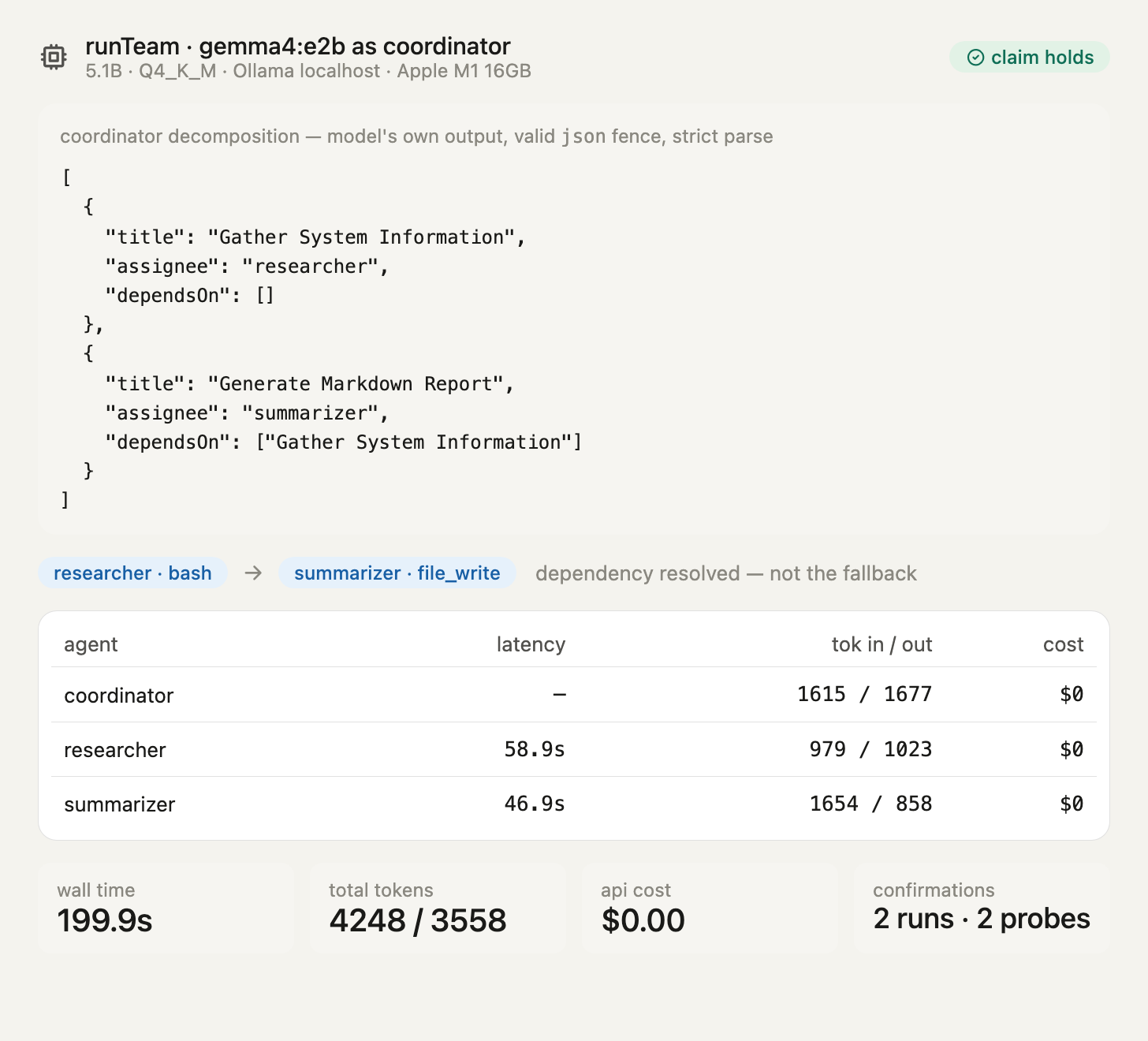
Part 2, runTeam with the local coordinator, one measured run:
| Task | Agent | Model | Latency | Tok in | Tok out | Tools | Cost |
|---|---|---|---|---|---|---|---|
| (decompose + synthesis) | coordinator | gemma4:e2b | — | 1615 | 1677 | (none) | $0 |
| Gather System Information | researcher | gemma4:e2b | 58.9 s | 979 | 1023 | bash | $0 |
| Generate Markdown Report | summarizer | gemma4:e2b | 46.9 s | 1654 | 858 | file_write | $0 |
| Total | 199.9 s wall | 4248 | 3558 | $0 |
The final report.md carried the real, correct values — Node v22.22.3, npm 10.9.8, macOS 26.5 (build 25F71), Darwin 25.5.0 … arm64 — so the workers didn’t just run, they produced accurate output. I re-ran the unmodified shipped file as a second confirmation: same outcome, runTasks 182.4 s and runTeam 155.5 s, same valid decomposition.
The honest headline on cost is $0, and on speed is minutes, not seconds — read on.
The friction nobody puts in the demo
This is the part you don’t get from a vendor page, and it’s the most useful part if you’re going to run this yourself.
1. It’s a “thinking” model — don’t cap maxTokens small. gemma4:e2b emits reasoning tokens in a separate channel before its answer. I reproduced the trap directly: a call with max_tokens: 10 returned empty content — the thinking ate the whole budget. The shipped example sets no maxTokens, so Ollama’s default applies and it works. But if you tighten the token budget to save memory, an empty coordinator response is exactly what triggers that silent fallback from the last section. On a thinking model, keep maxTokens generous.
2. Plan for ~16 GB RAM, and expect swap. The 7.16 GB Q4 model pushed my 16 GB machine into swap (~6.8–7.3 GB used during runs). It completed correctly, but the bigger gemma4:e4b (9.6 GB) would be worse here. Set expectations: e2b wants 16 GB and still swaps; go bigger and you need more.
3. Slow but functional. Per-call latency ran 5–25 s; a full demo (Part 1 + Part 2) is about 6 minutes. That’s fine for a “$0, private, runs overnight” story; it is not interactive-snappy.
4. No quantization pathologies — and you don’t need the sampling knobs for this model. Across every run: zero repetition loops, zero hallucinated tool schemas, zero invalid JSON. The repo’s local-quantized.ts example (topK / minP / repetition_penalty tuning) targets other MoE quants that misbehave — you don’t need it for gemma4:e2b. Which is a nice segue, because tuning does come back to matter in the hybrid case.
Going hybrid: cloud coder, local reviewer (and where it broke)
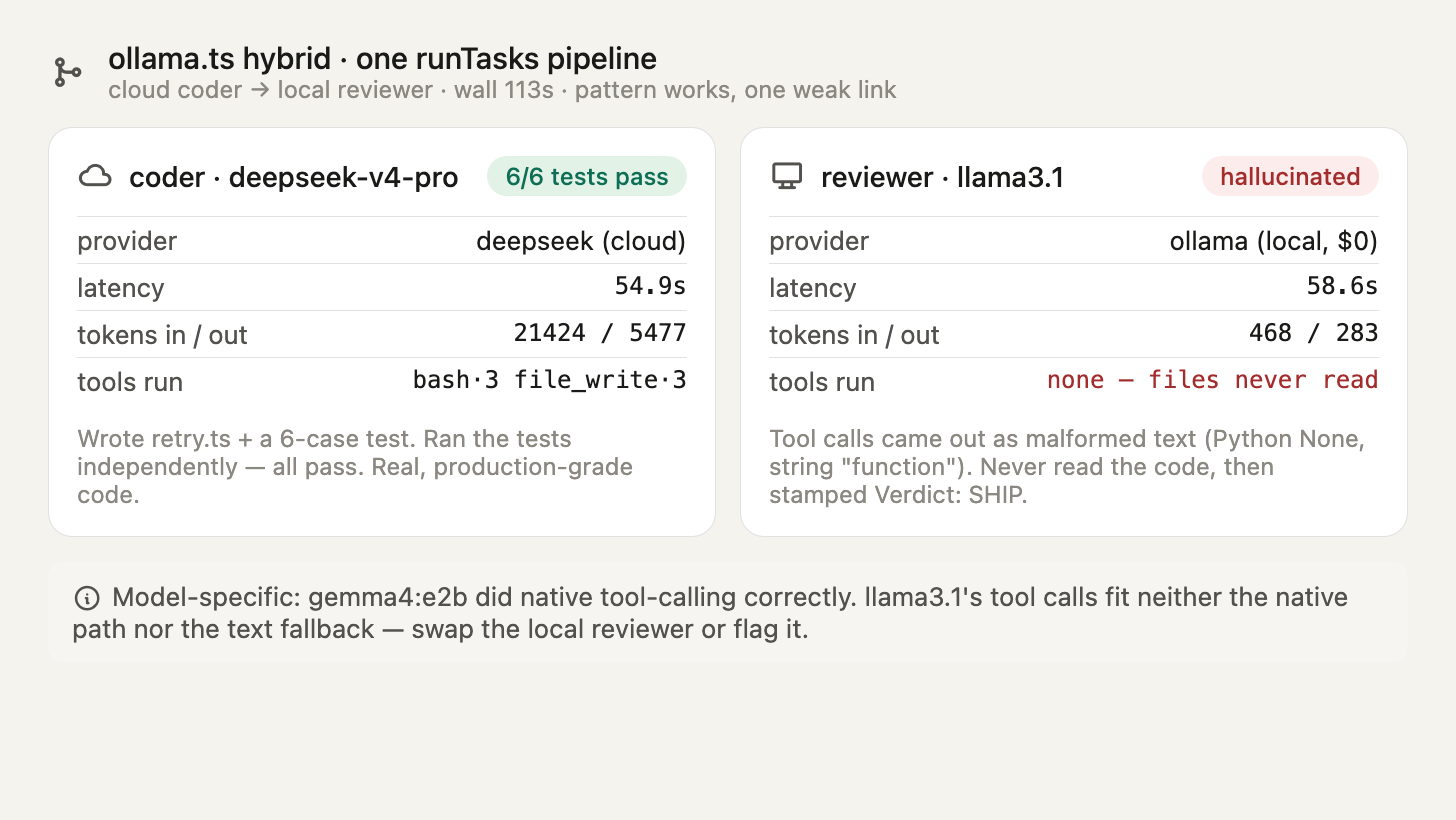
The same baseURL trick lets you mix cloud and local in one pipeline: send the hard, non-sensitive work to a strong cloud model and keep the rest local. The shipped ollama.ts does exactly this — a coder plus a reviewer. I ran a faithful copy with a cloud coder (DeepSeek) and the shipped local reviewer (llama3.1 over Ollama).
| Agent | Provider | Model | Tools executed | Verdict |
|---|---|---|---|---|
| coder | deepseek (cloud) | deepseek-v4-pro | bash×3, file_write×3 | excellent |
| reviewer | ollama (local) | llama3.1 | none | hallucinated |
The cloud coder passed for real. DeepSeek wrote a clean retry.ts (exponential backoff, shouldRetry, withRetry) and a 6-case test file. I ran the tests independently: 6 passed, 0 failed.
The local llama3.1 reviewer failed substantively — twice. It never read the files (tools: [], ~468 input tokens against the ~2,400 the two files would cost), then hallucinated a review: it called TypeScript code “try-except blocks” (that’s Python), described a 3-export module as “a single function,” and rubber-stamped Verdict: SHIP. Worse, the run reported success: true. A confident review of code it never opened.
Root cause, precisely: llama3.1 didn’t emit native tool_calls — it narrated the call as text, and the text was malformed for the safety-net extractor (invalid JSON in one run, a wrong function-as-string shape in the repro). Neither the native path nor the fallback fired, so no file was ever read. This is model-specific: gemma4:e2b in the 100%-local example emitted correct native tool calls and every tool executed.
Fixing the local reviewer: a two-part fix, not a model swap
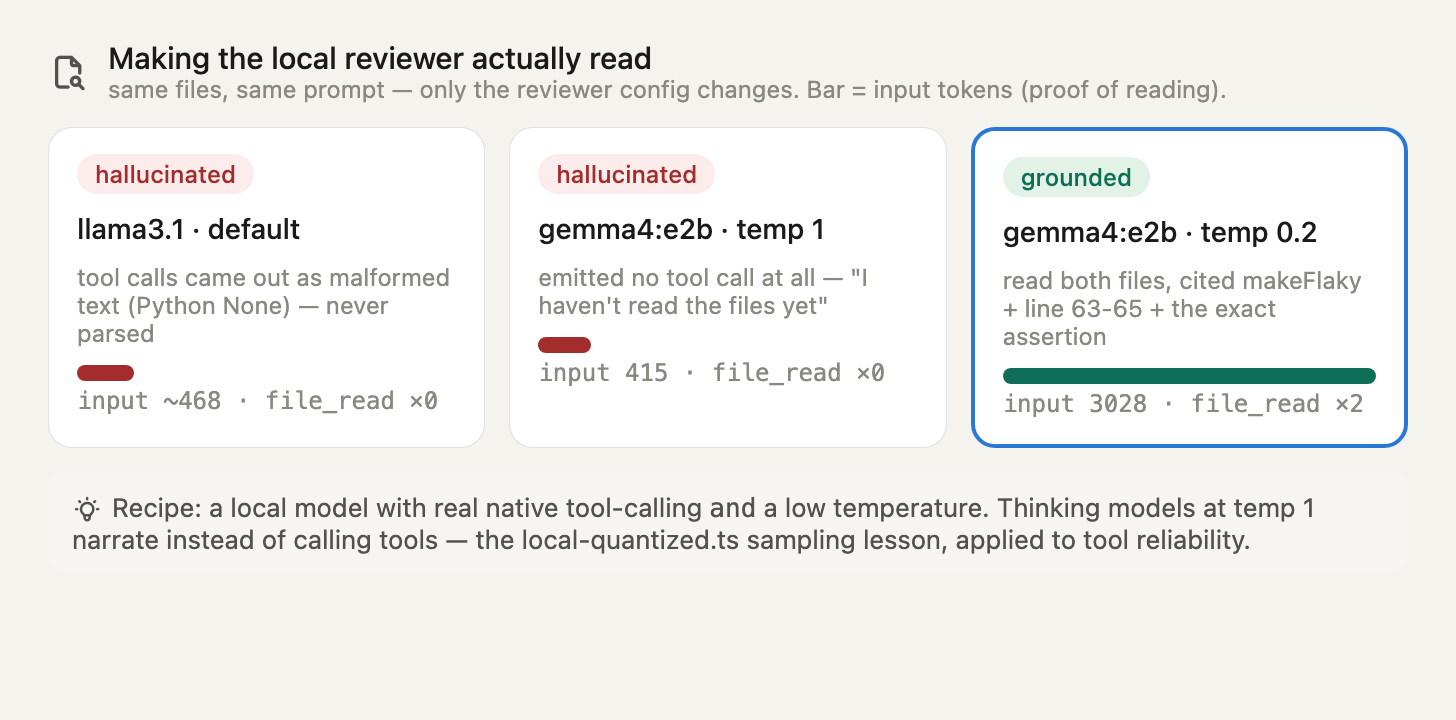
The obvious fix is “swap the reviewer to a model with real tool-calling.” Necessary, but not sufficient — the temperature matters just as much. Same files, same reviewer prompt, only the reviewer config changes:
| Reviewer config | file_read executed | Input tok | Outcome |
|---|---|---|---|
| llama3.1 (default) | none | 335–468 | malformed text tool-calls → hallucinated review |
| gemma4:e2b @ temp 1 (its default) | none | 415 | emitted no tool call → “I haven’t read the files yet” |
| gemma4:e2b @ temp 0.2, topP 0.9 | file_read ×2 | 3028 | read both files → grounded review |
Only the last row actually read the code — you can see it in the input tokens jumping from 415 to 3028, and in the review citing real specifics (the makeFlaky helper, testFailureExhaustion at lines 63–65, the exact 'permanent failure' assertion string).
Why temperature? gemma4:e2b is a thinking model with a default temperature: 1. At temp 1 it stochastically narrated “I’ll read them later” and emitted no tool call, so the agent loop ended after one turn. At temp 0.2 it deterministically followed “read first.” This is the same “tame your sampling for local models” lesson from local-quantized.ts — shown here to govern tool-call reliability, not just repetition. The recipe for a working local reviewer: (1) a model with real native tool-calling, and (2) a low temperature. With both, the local reviewer genuinely reads and reviews, at $0.
When to go fully local vs hybrid
- Fully local when data residency is the hard constraint: nothing leaves the machine, $0 cost, and — as shown — even the coordinator can be local. The price is RAM and latency (minutes, not seconds).
- Hybrid when one step genuinely needs a frontier model (the coder above) but the rest can stay home. The plumbing is sound — cloud and local in one
runTaskspipeline viabaseURL. Just pick your local agents for solid native tool-calling and tame their temperature, or you get a confident reviewer that never read the code.
There’s also a higher-level angle worth a link: in Part 2 I let the local model be the coordinator. If you want the mechanics of how a goal becomes a task DAG in this framework, I wrote that up in Goal In, DAG Out. The surprise of this post is that the model driving that decomposition can be 5B and running on your laptop.
Run it
npm install @open-multi-agent/coreYou’ll need Ollama running with the model pulled:
ollama pull gemma4:e2b # ~7 GB; wants ~16 GB RAM to run comfortably# then run the example from the repo (remember: no_proxy=localhost if you use a proxy)Three example files to read, in increasing spice: gemma4-local.ts (100% local, both runTasks and runTeam), local-quantized.ts (sampling knobs for MoE quants that misbehave), and ollama.ts (the hybrid — cloud + local in one pipeline).
One honest caveat: local tool-calling reliability varies a lot by model — gemma4:e2b was solid, llama3.1 was not in this task — and the project’s production validation is still early. If you run a local team of your own, I’d like to hear which local models emitted clean native tool calls and which didn’t.
Originally published on dev.to.