目标进,DAG 出:open-multi-agent 如何把一个目标变成任务 DAG
你手画了那张图。然后需求变了。
多数 TypeScript 智能体框架都要你自己画图。你声明节点、接好边、决定什么在什么之后跑、在哪里分支、在哪里汇合。这套能用——直到目标一变,你又回到图编辑器里,重新接一条你已经搭过一遍的流水线。
还有另一种建模方式:描述目标,让一个协调器替你构建那张图。
这正是 open-multi-agent 里 runTeam() 做的事。你交给它一个团队和一句话,它还你一个结果。中间,一个协调器智能体把目标拆解成任务 DAG、把任务分派给你的智能体、并行跑相互独立的那些、再综合出最终答案。没有边要接。
这篇讲的就是那个「中间」发生了什么,因为机制本身才是重点。
那一次调用
import { OpenMultiAgent } from '@open-multi-agent/core'
const orchestrator = new OpenMultiAgent({ defaultModel: 'deepseek-v4-flash', defaultProvider: 'deepseek',})
const team = orchestrator.createTeam('research', { name: 'research', agents: [ { name: 'researcher', model: 'deepseek-v4-flash', provider: 'deepseek', systemPrompt: 'You research topics and gather concrete facts.' }, { name: 'writer', model: 'deepseek-v4-flash', provider: 'deepseek', systemPrompt: 'You turn research notes into clear prose.' }, ], sharedMemory: true,})
const result = await orchestrator.runTeam( team, 'Research the tradeoffs of TypeScript decorators, covering the stage-3 standard ' + 'versus the legacy experimental implementation, runtime and bundle-size cost, and ' + 'current framework support, then write a clear 500-word explainer for a team ' + 'deciding whether to adopt them.',)
console.log(result.agentResults.get('coordinator')?.output)钻进底层之前,先注意三件事:
- 你从没声明任何任务图。你用大白话写下了目标。
- 每个智能体声明自己的
model。编排器的defaultModel给协调器用;工作智能体各自带自己的。(把deepseek换成任何支持的提供方:Anthropic、OpenAI、Gemini、本地模型,等等。) - 这个目标是故意写具体的。一个简短、单从句的目标会被当成简单任务、完全跳过协调器;这点下面细说。
跑一下,框架就会做七件事。下面按顺序来。
第 1 步:协调器拆解目标
runTeam() 临时拉起一个叫 coordinator 的智能体。它不在你的名册里。框架为这次运行创建它,跑完就丢。它拿到你的目标、你那些智能体的名字,以及一条指令:
Decompose the following goal into tasks for your team (researcher, writer). Return ONLY the JSON task array in a
jsoncode fence.
协调器回一个 JSON 任务规格数组。这是上面那次运行里真实的一份拆解:
[ { "title": "Research stage-3 vs legacy experimental decorators", "description": "Gather the syntax and behavioral differences ...", "assignee": "researcher", "dependsOn": [] }, { "title": "Research runtime and bundle-size cost of decorators", "description": "Investigate helper code, tree-shaking, benchmarks ...", "assignee": "researcher", "dependsOn": [] }, { "title": "Research current framework support for decorators", "description": "Survey Angular, NestJS, TypeORM, MobX ...", "assignee": "researcher", "dependsOn": [] }, { "title": "Write 500-word explainer on decorator tradeoffs", "description": "Using the three research outputs, write the explainer ...", "assignee": "writer", "dependsOn": [ "Research stage-3 vs legacy experimental decorators", "Research runtime and bundle-size cost of decorators", "Research current framework support for decorators" ] }]每个任务带一个 title、一个 description(被指派的智能体真正会收到的指令)、一个 assignee,以及 dependsOn——它必须等待的任务标题列表。最后那个字段就是 DAG,以数据而非接线的形式表达。注意协调器选择把调研拆成三个相互独立的任务,再让写作任务依赖这三个。具体怎么拆每次运行都会变,因为协调器是个 LLM;这只是其中一份真实的计划。
这一步多花一次 LLM 调用。协调器默认以 maxTurns 为 3 运行。把这笔开销记在心里;文末会再回来谈。
第 2 步:任务变成依赖图
这些规格被装进一个 TaskQueue。基于标题的 dependsOn 引用被解析成真实的任务 ID,于是队列知道了图真正的形状。一个任务只有在它依赖的每个任务都完成后,才会变「就绪」。没有依赖的任务立刻就绪。
如果协调器没能返回可用的 JSON,运行不会崩。框架回退到每个智能体一个任务,每个任务都拿原始目标当描述。你得到的是一次降级运行,而不是一个异常。
第 3 步:未分派的任务找到归属
协调器通常会填好 assignee,但它并非必须填。任何没被分派的任务都交给 Scheduler,由它指派给某个智能体。默认策略是 dependency-first;你也可以选 round-robin、least-busy 或 capability-match——后者会拿每个智能体的名字和系统提示去给任务打分。
第 4 步:执行,默认并行
任务通过一个 AgentPool 跑。相互独立的任务(dependsOn 里没有待办项)并发跑,上限是 maxConcurrency,默认 5。有依赖的任务等到它们的输入完成、才变就绪并派发。在上面那次真实运行里,三个调研任务没有依赖,于是它们在同一瞬间一起启动、一起跑;写作任务等到三个都完成。这些你一个都没排过期。图的形状决定了什么能重叠,而池子会在上限允许的范围内尽量并行地跑。
第 5 步:每个结果都持久化到共享内存
每个任务完成后,它的输出会被写进团队的共享内存。writer 就是这样看到 researcher 的发现的:等写作任务就绪时,三份调研结果已经在内存里。智能体通过这个共享存储沟通,而不是靠你把一次调用的输出穿针引线塞进下一次。
第 6 步:协调器综合
队列排空后,协调器再跑第二次。这一遍读取每个任务的输出,写出针对目标的最终答案。这就是你从 agentResults.get('coordinator') 读到的结果。
想看计划本身、而不是最终的散文?任务记录在结果的 result.tasks 上(每条带 title、assignee、status 和 dependsOn),而你只想要计划、不想执行任何东西的话,调 runTeam(team, goal, { planOnly: true })。
第 7 步:你拿到一个结构化结果
runTeam() 解析为一个 TeamRunResult:一个以智能体名为键的 agentResults 映射(这里是 coordinator、researcher、writer)、一个 totalTokenUsage 数值,以及带状态和指标的 tasks 记录列表。发生过的一切事后都可检视。
一次真实运行长什么样
这是上面那段代码跑在 DeepSeek(deepseek-v4-flash)上的实际输出:
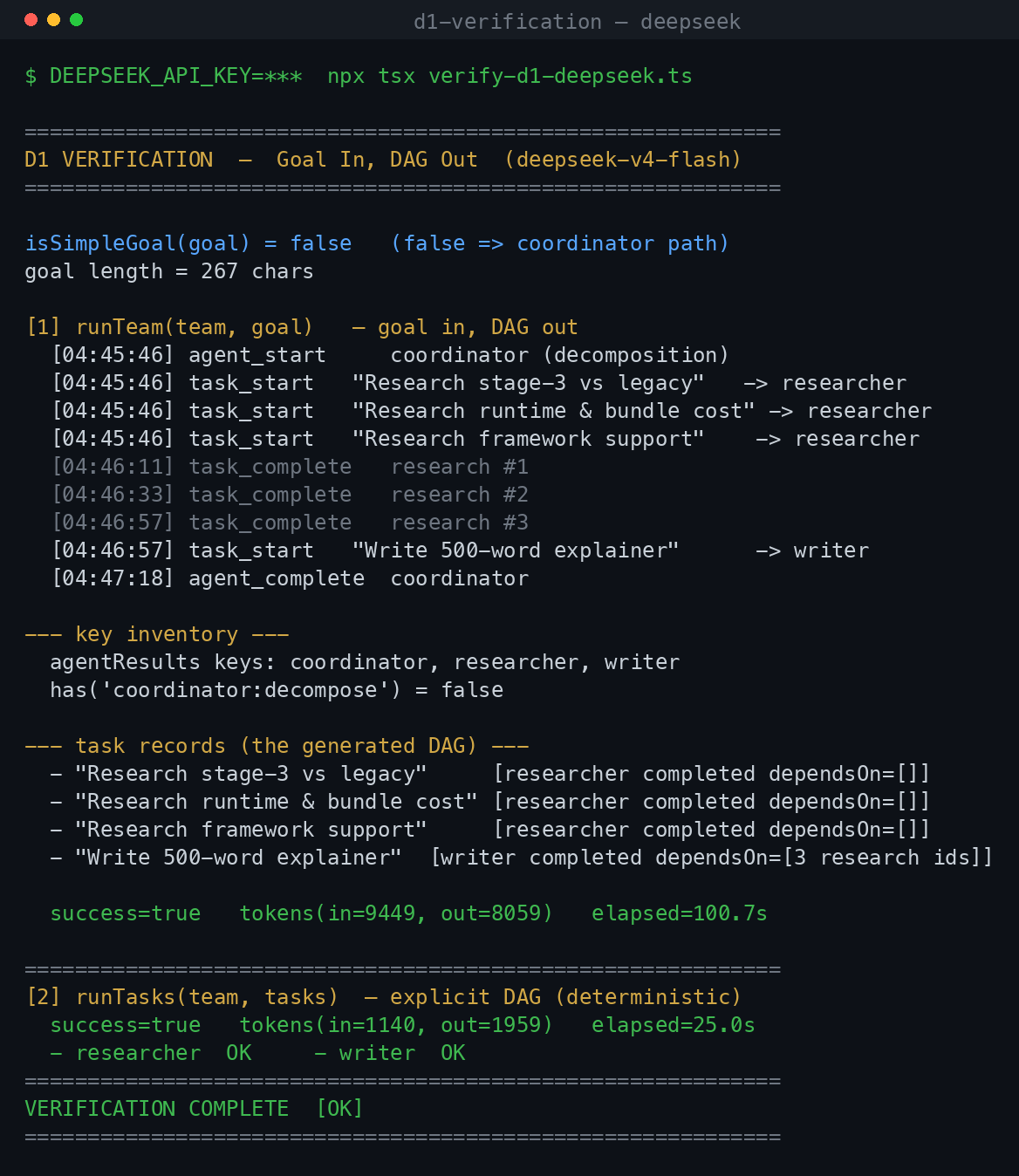
协调器把目标拆成三个并行的调研任务和一个有依赖的写作任务,并发跑完调研、持久化每份结果,再综合出最终的讲解稿。runTeam() 以 success=true 收尾;下面那个显式的 runTasks() 版本跑法一样。
当一个任务失败
失败不会越过自己的下游级联扩散。一个失败的任务被标记为 failed,任何依赖它的任务都停在 blocked。每个不依赖那次失败的任务都会一直跑到完成。你以部分结果收尾,外加一份清楚的记录、标明哪条分支断了,而不是一个错误把整张图都拖垮。
什么时候你不该用协调器
目标优先不是银弹,框架对这点直言不讳。
简单目标完全跳过协调器。 如果目标很短(200 字符或更少)且不含任何协调指令,runTeam() 会走短路:它挑一个最匹配的智能体直接跑,没有拆解、没有综合那一遍。没理由为「总结这段话」付两次额外的 LLM 调用。(上面快速上手的目标之所以写得这么详细,正是为此:一句话的目标会被直接路由给单个智能体。)
当你需要确定性时,自己写图。 协调器是个 LLM,所以它的拆解可能每次运行都不一样(上面的例子一次产出三个调研任务,另一次只产出一个)。如果你需要每次都是完全相同的流水线(CI、受监管的工作流、任何你必须精确推理的东西),用 runTasks() 直接把 DAG 喂给它:
const result = await orchestrator.runTasks(team, [ { title: 'Research decorator tradeoffs', description: 'Gather concrete pros and cons of TypeScript decorators.', assignee: 'researcher', }, { title: 'Write the explainer', description: 'Using the research notes, write a 500-word explainer.', assignee: 'writer', dependsOn: ['Research decorator tradeoffs'], },])同一个队列、同一个调度器、同样的并行执行。你只是自己拥有了那张图,而不是去要一张。(你也可以把协调器生成的计划钉死、再确定性地重放它,但那是另一篇的事了。)
所以取舍很具体:
runTeam()是目标优先:灵活,多出两次 LLM 调用的规划开销,一份每次运行都可能变的计划。runTasks()是图优先:确定,每次运行更便宜,但图得你来维护。
目标优先 vs 图优先
这才是你选框架时真正要紧的区分。图优先的工具(你来接线节点)用维护成本换控制和确定性。目标优先(你来描述结果)用多出一遍规划和一份不确定的计划换灵活。open-multi-agent 把两者都装在同一套 API 后面,于是你可以从目标优先起步,在那些必须锁死的路径上再降到显式图。关于这道分野我写过更多,见目标驱动的智能体编排 vs 显式图。
试一下
npm install @open-multi-agent/coreteam-collaboration 示例是最小的端到端 runTeam() 运行。如果你想看看这套能走多远,Gemma 4 本地示例把一个 5B 的本地模型放到协调器的位置上:JSON 拆解和综合都在你自己的机器上完成。
一个诚实的提醒:社区和生产环境的验证都还很早。如果你拿协调器跑了真实的负载,我很想听听它的计划在哪里站得住、又在哪里你不得不降回 runTasks()。