Goal In, DAG Out: How Open-Multi-Agent Turns a Goal into a Task DAG
You wrote the graph by hand. Then the requirements changed.
Most TypeScript agent frameworks make you draw the graph yourself. You declare the nodes, wire the edges, decide what runs after what, where it branches, where it joins. It works, right up until the goal shifts and you are back in the graph editor re-wiring a pipeline you already built once.
There is another way to model this: describe the goal, and let a coordinator build the graph for you.
That is what runTeam() does in open-multi-agent. You hand it a team and a sentence. It hands back a result. In between, a coordinator agent decomposes the goal into a task DAG, assigns the tasks to your agents, runs the independent ones in parallel, and synthesizes the final answer. There are no edges to wire.
This post is about what happens in that “in between,” because the mechanism is the whole point.
The one call
import { OpenMultiAgent } from '@open-multi-agent/core'
const orchestrator = new OpenMultiAgent({ defaultModel: 'deepseek-v4-flash', defaultProvider: 'deepseek',})
const team = orchestrator.createTeam('research', { name: 'research', agents: [ { name: 'researcher', model: 'deepseek-v4-flash', provider: 'deepseek', systemPrompt: 'You research topics and gather concrete facts.' }, { name: 'writer', model: 'deepseek-v4-flash', provider: 'deepseek', systemPrompt: 'You turn research notes into clear prose.' }, ], sharedMemory: true,})
const result = await orchestrator.runTeam( team, 'Research the tradeoffs of TypeScript decorators, covering the stage-3 standard ' + 'versus the legacy experimental implementation, runtime and bundle-size cost, and ' + 'current framework support, then write a clear 500-word explainer for a team ' + 'deciding whether to adopt them.',)
console.log(result.agentResults.get('coordinator')?.output)Three things to notice before we go under the hood:
- You never declared a task graph. You wrote the goal in plain English.
- Each agent declares its own
model. The orchestrator’sdefaultModelis used by the coordinator; worker agents carry their own. (Swapdeepseekfor any supported provider: Anthropic, OpenAI, Gemini, a local model, and so on.) - The goal is deliberately specific. A short, single-clause goal is treated as a simple task and skips the coordinator entirely; more on that below.
Run this and the framework does seven things. Here they are, in order.
Step 1: A coordinator decomposes the goal
runTeam() spins up a temporary agent called coordinator. It is not part of your roster. The framework creates it for this run and discards it afterward. It receives your goal, the names of your agents, and one instruction:
Decompose the following goal into tasks for your team (researcher, writer). Return ONLY the JSON task array in a
jsoncode fence.
The coordinator answers with a JSON array of task specs. Here is a real decomposition from the run above:
[ { "title": "Research stage-3 vs legacy experimental decorators", "description": "Gather the syntax and behavioral differences ...", "assignee": "researcher", "dependsOn": [] }, { "title": "Research runtime and bundle-size cost of decorators", "description": "Investigate helper code, tree-shaking, benchmarks ...", "assignee": "researcher", "dependsOn": [] }, { "title": "Research current framework support for decorators", "description": "Survey Angular, NestJS, TypeORM, MobX ...", "assignee": "researcher", "dependsOn": [] }, { "title": "Write 500-word explainer on decorator tradeoffs", "description": "Using the three research outputs, write the explainer ...", "assignee": "writer", "dependsOn": [ "Research stage-3 vs legacy experimental decorators", "Research runtime and bundle-size cost of decorators", "Research current framework support for decorators" ] }]Each task carries a title, a description (the actual instruction the assigned agent will receive), an assignee, and dependsOn, a list of task titles it must wait for. That last field is the DAG, expressed as data instead of as wiring. Notice the coordinator chose to split the research into three independent tasks and make the write task depend on all three. The exact split varies between runs, because the coordinator is an LLM; this was one real plan.
This step costs one extra LLM call. The coordinator runs with a maxTurns of 3 by default. Keep that overhead in mind; we come back to it at the end.
Step 2: The tasks become a dependency graph
The specs load into a TaskQueue. The title-based dependsOn references resolve to real task IDs, so the queue knows the true shape of the graph. A task becomes “ready” only once every task it depends on has completed. Tasks with no dependencies are ready immediately.
If the coordinator fails to return usable JSON, the run does not crash. The framework falls back to one task per agent, each handed the original goal as its description. You get a degraded run, not an exception.
Step 3: Unassigned tasks get an owner
The coordinator usually fills in assignee, but it does not have to. Any task left unassigned is handed to the Scheduler, which assigns it to an agent. The default strategy is dependency-first; you can also pick round-robin, least-busy, or capability-match, which scores each agent’s name and system prompt against the task.
Step 4: Execution, parallel by default
Tasks run through an AgentPool. Independent tasks (nothing pending in their dependsOn) run concurrently, up to maxConcurrency, which defaults to 5. Dependents wait until their inputs are done, then become ready and dispatch. In the real run above, the three research tasks had no dependencies, so they all started in the same instant and ran together; the write task waited until all three finished. You did not schedule any of that. The graph shape decides what can overlap, and the pool runs as much of it in parallel as the limit allows.
Step 5: Every result is persisted to shared memory
After each task completes, its output is written to the team’s shared memory. That is how the writer sees the researcher’s findings: by the time the write task is ready, the three research results are already in memory. Agents communicate through this shared store rather than by you threading outputs from one call into the next.
Step 6: The coordinator synthesizes
Once the queue drains, the coordinator runs a second time. This pass reads every task output and writes the final answer to the goal. This is the result you read from agentResults.get('coordinator').
Want to inspect the plan itself rather than the final prose? The task records are on the result as result.tasks (each with title, assignee, status, and dependsOn), and you can get just the plan without executing anything by calling runTeam(team, goal, { planOnly: true }).
Step 7: You get a structured result
runTeam() resolves to a TeamRunResult: an agentResults map keyed by agent name (here coordinator, researcher, writer), a totalTokenUsage figure, and the tasks record list with statuses and metrics. Everything that happened is inspectable after the fact.
What one real run looks like
Here is the actual output, running the code above against DeepSeek (deepseek-v4-flash):
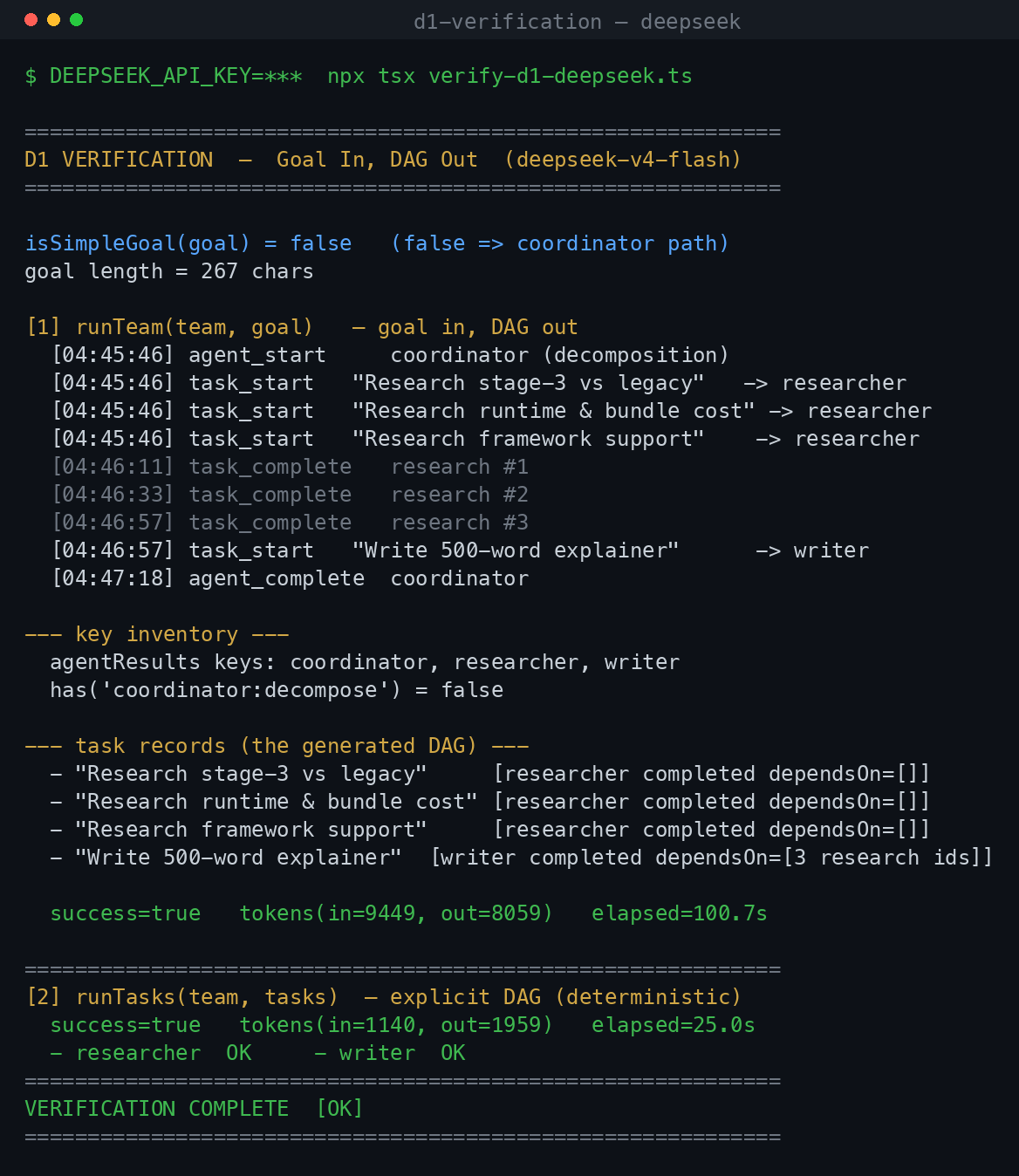
The coordinator decomposed the goal into three parallel research tasks and one dependent write task, ran the research concurrently, persisted each result, and synthesized the final explainer. runTeam() finished success=true; the explicit runTasks() version below ran the same way.
When a task fails
Failures do not cascade past their own dependents. A failed task is marked failed, and any task that depends on it stays blocked. Every task that does not depend on the failure keeps running to completion. You end the run with partial results plus a clear record of which branch broke, instead of one error tearing down the whole graph.
When you should NOT use the coordinator
Goal-first is not a silver bullet, and the framework is explicit about that.
Simple goals skip the coordinator entirely. If the goal is short (200 characters or fewer) and contains no coordination directives, runTeam() short-circuits: it picks the best-matching agent and runs it directly, with no decomposition and no synthesis pass. There is no reason to pay for two extra LLM calls to “Summarize this paragraph.” (This is exactly why the quickstart goal above is spelled out in detail: a one-liner would have been routed straight to a single agent.)
When you need determinism, write the graph yourself. The coordinator is an LLM, so its decomposition can vary run to run (the example above produced three research tasks on one run and a single research task on another). If you need the exact same pipeline every time (CI, regulated workflows, anything you have to reason about precisely), use runTasks() and supply the DAG directly:
const result = await orchestrator.runTasks(team, [ { title: 'Research decorator tradeoffs', description: 'Gather concrete pros and cons of TypeScript decorators.', assignee: 'researcher', }, { title: 'Write the explainer', description: 'Using the research notes, write a 500-word explainer.', assignee: 'writer', dependsOn: ['Research decorator tradeoffs'], },])Same queue, same scheduler, same parallel execution. You just own the graph instead of asking for one. (You can also pin a coordinator-generated plan and replay it deterministically, but that is a separate post.)
So the tradeoff is concrete:
runTeam()is goal-first: flexible, two extra LLM calls of planning overhead, a plan that can change between runs.runTasks()is graph-first: deterministic and cheaper per run, but you maintain the graph.
Goal-first vs graph-first
This is the distinction that actually matters when you choose a framework. Graph-first tools (you wire the nodes) trade maintenance for control and determinism. Goal-first (you describe the outcome) trades an extra planning pass and a non-deterministic plan for flexibility. open-multi-agent ships both behind one API, so you can start goal-first and drop to an explicit graph on the paths that have to be locked down. I wrote more about that split in Goal-Driven Agent Orchestration vs Explicit Graphs.
Try it
npm install @open-multi-agent/coreThe team-collaboration example is the smallest end-to-end runTeam() run. If you want to see how far this goes, the Gemma 4 local example puts a 5B local model in the coordinator seat: it does the JSON decomposition and the synthesis on your own machine.
One honest caveat: community and production validation are still early. If you run the coordinator on a real workload, I would like to hear where its plan held up and where you had to drop to runTasks().
Originally published on dev.to.